DeepSeek深夜突袭:V3小版本更新为何引爆全球开发者?

作者:像素 | 智沅 3月24日凌晨1点,DeepSeek突然发布V3-0324版本更新。看似仅将参数从6710亿微调至6850亿,却通过三项技术革新掀起风暴: 开发者惊呼:“这哪是更新?简直是重做了一套模型!” 实测数据让程序员集体沸腾: 某科技公司CTO直言:“用免费模型干翻闭源巨头,这是要革SaaS行业的命!” DeepSeek此次祭出商业友好型开源协议: 网友戏称:“OpenAI律师函还在路上,中国开发者已经用上新模型了。” 尽管官方称此次是“常规升级”,但蛛丝马迹显露野心: 行业分析师预测:“2025年或成开源模型反超闭源的转折点。” 当开发者发现,一个深夜推送的免费模型竟能生成媲美Claude 3.7的代码,AI技术平民化的时代已然降临。这场突袭不仅关乎技术突破,更是开源生态对封闭霸权的一次漂亮反击——而你我,正在见证历史。 本文数据综合自DeepSeek技术白皮书、HuggingFace社区实测及开发者访谈DeepSeek深夜突袭:V3小版本更新为何引爆全球开发者?
一、深夜突袭!参数微调暗藏三大“杀手锏”

二、代码生成开挂:单挑全球最强闭源模型
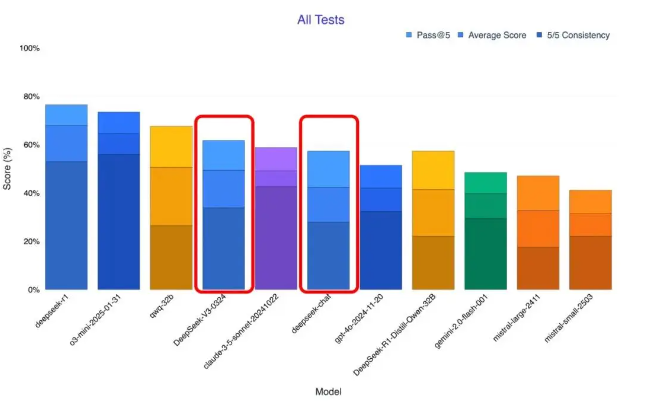
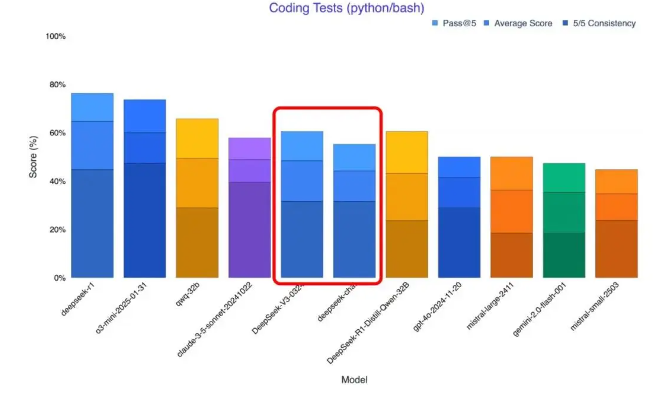
三、MIT协议核爆:开发者生态大地震
✅ 允许商用:企业可免费集成至客服、销售系统,代码生成覆盖率达27%。
✅ 零成本调用:API定价仅GPT-4o的7%(输入0.5元/百万token)。
✅ 生态反哺:HuggingFace开源24小时下载量破10万,衍生出自动化建站工具、低代码游戏引擎等20+项目。
四、更新背后的阳谋:给V4和R2铺路?
结语:小更新掀起开源革命
免责声明:本文不代表米塔之家立场,且不构成投资建议,请谨慎对待。






